面经总结v1.0
本博客内容来源于牛客网整理的他人面经。
OSI 七层协议模型
开放式系统互联通信参考模型(Open System Interconnection Reference Model,缩写为 OSI),简称为OSI模型(OSI model),一种概念模型,由国际标准化组织提出,一个试图使各种计算机在世界范围内互连为网络的标准框架。
它将计算机⽹络体系结构划分为7层,每层都为上⼀层提供了良好的接⼝。
分层结构
主要分为以下七层(从下⾄上):物理层、数据链路层、⽹络层、传输层、会话层、表示层、应⽤层。
物理层(比特):在物理媒体上为数据端设备透明地传输原始比特流;主要定义数据终端设备和数据通信设备的物理与逻辑连接方法。IEEE 802.1A、IEEE 802.2
数据链路层(帧):接收来自物理层的 bit 流封装成帧,将网络层传来的IP数据组装成帧,并进行差错控制、流量控制、传输管理等。ARP、MAC、 FDDI、Ethernet、Arpanet、PPP、PDN
网络层(数据报,packet):负责对通信子网间的数据包进行路由选择,实现流量控制、拥塞控制、差错控制和网际互连等功能。(把网络层的协议数据单元(分组)从源端传到目的端,为分组交换网上的不同主机提供通信服务。)IP、ICMP、ARP、RARP
传输层(数据段segment:报文段TCP,用户数据报UDP)负责主机中两个进程间的通信,为端到端连接提供可靠的传输服务,提供流量控制、差错控制、服务质量、数据传输管理等服务。TCP、UDP
会话层:管理主机之间的会话进程,即负责建⽴、管理、终⽌进程之间的会话。SMTP、DNS
会话层还利用在数据中插入校验点来实现数据的同步,访问验证和会话管理在内的建立和维护应用之间通信的机制。如服务器验证用户登录便是由会话层完成的。使通信会话在通信失效时从校验点继续恢复通信。比如说建立会话,如 session 认证、断点续传。
表示层:处理在两个通信系统中交换信息的表示方式。提供格式化的表示和转换数据服务,将准备交换的数据从适合于某⼀⽤户的抽象语法,转换为适合于OSI系统内部使⽤的传送语法。数据的压缩和解压缩, 加密和解密等⼯作都由表示层负责,⽐如说图像、视频编码解,数据加密。Telnet、SNMP
应用层:为操作系统或网络应用程序提供访问网络服务的接口。FTP、TFTP、Telnet、HTTP、DNS
应用层协议
FTP
FTP(File Transport Protocol,文件传输协议)是网络上两台计算机传送文件的协议,运行在TCP之上,是通过Internet将文件从一台计算机传输到另一台计算机的一种途径。FTP在客户机和服务器之间需要建立两条TCP连接,一条用于传送控制信息(使用21端口),另一条用于传输文件内容(使用20号端口)。TFTP
TFTP(Trivial File Transfer Protocol,简单文件传输协议)是用来在客户机与服务器之间进行简单文件传输的协议,提供不复杂、开销不大的文件传输服务。TFTP建立在UDP之上,提供不可靠的数据流传输服务,不提供存取授权与认证机制,使用超时重传方式来保证数据的到达。FTP和TFTP记忆区别,两者都是文件传输协议。FTP是文件传输协议,是基于TCP之上,比较复杂;TFTP是建立在UDP上,比较简单。
HTTP
HTTP(Hypertext Transfer Protocol,超文本传输协议)是用于从WWW服务器传输超文本到本地浏览器的传送协议。HTTP建立在TCP之上。SMTP
SMTP(Simple Mail Transfer Protocol,简单邮件传输协议)建立在TCP之上,是一种提供可靠且有效的电子邮件传输的协议。SMTP是建立在FTP文件传输服务上的一种邮件服务。DHCP
DHCP(Dynamic Host Configuration,动态主机配置协议)建立在UDP之上,基于客户机/服务器模型设计的。DHCP分配的IP地址可以分为三种方式,分别是固定分配、动态分配和自动分配。Telnet
Telnet(远程登录协议)是登录和仿真程序,建立在TCP之上,它的基本功能是允许用户登录进入远程计算机系统。DNS
DNS(Domain Name System,域名系统)在Internet上域名与IP地址之间是一一对应的,域名虽然便于人们记忆,但机器之间只能互相认识IP地址,它们之间的转换工作称为域名解析,域名解析需要由专门的域名解析服务器来完成,DNS就是进行域名解析的服务器。SNMP
SNMP(Simple Network Management Protocol,简单网络管理协议)是为了解决Internet上的路由器管理问题而提出的,它可以在IP、IPX、AppleTalk和其他传输协议上使用。
————————————————
应用层协议[原文链接:https://blog.csdn.net/freee12/article/details/114411950]
三次握手、四次挥手
三次握手
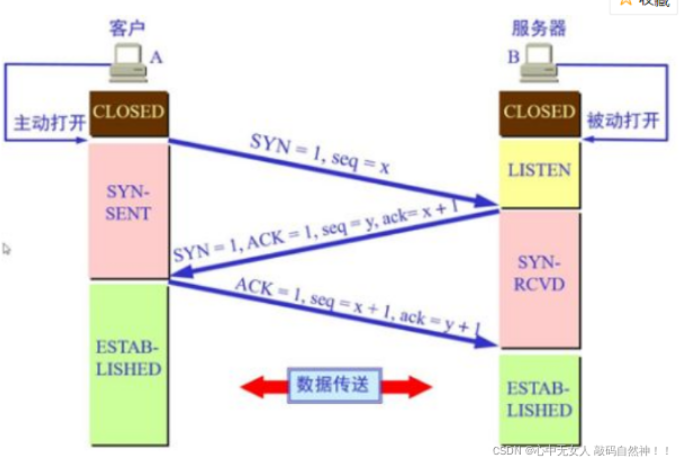
握手之前主动打开连接的客户端结束CLOSED阶段,被动打开的服务器端也结束CLOSED阶段,并进入LISTEN阶段。随后开始“三次握手”:
a:首先客户端先向服务器端发送一个TCP报文
标记位为SYN,表示“请求建立新连接”;
序号为Seq=X(X一般为1)(传输信息的时候每个数据包的序号);
随后客户端进入SYN-SENT阶段(请求连接的阶段)。
b:服务器端收到来自客户端的TCP报文之后,结束LISTEN阶段。并返回一段报文
标志位为SYN和ACK,表示“确认客户端的报文Seq序号有效,服务器能正常接收客户端发送的数据,并同意创建新连接”(即告诉客户端,服务器收到了你的数据);
序号为Seq=y;(返回一个收到信息的数据包 并给其标序号为y)
确认号为Ack=x+1,表示收到客户端的序号Seq并将其值加1作为自己确认号Ack的值(两端配对 接收到消息 并反馈的过程;随后服务器端进入SYN-RCVD阶段。
ACK:代表确认收到消息
c:客户端接收到来自服务器确认收到数据的TCP报文后,明确了从客户端到服务器的数据传输是正常的,结束SYN-SENT阶段,并返回一段TCP报文
标志位为ACK,表示“确认收到服务器端同意连接的信号”(即告诉服务器,我知道你收到我发的数据了);
序号为Seq=x+1,表示收到服务器端的确认号Ack,并将其值作为自己的序号值;
确认号为Ack=y+1,表示收到服务器端序号Seq,并将其值加1作为自己的确认号Ack的值;
随后客户端进入ESTABLISHED阶段。(即成功建立了连接)
d:关于确认号Ack和数据包的序号Seq值得变化
**Ack确认号:**就是确认收到消息后 返回给 发送端的 序号(Ack = 发起方的Seq + 1) 即就是下次发送的端的seq序号
ACK确认序号(Seq)有效:确认发送的数据包的成功到达
**Seq:序号:**给每个数据包一个序号,保证接受端可以按序收到数据包(首次握手的时候 Seq = 上次握手的时候的Ack值,如果没有 则可以是任意值)
在客户端与服务器端传输的TCP报文中,双方的确认号Ack和序号Seq的值,都是在彼此Ack和Seq值的基础上进行计算的,这样做保证了TCP报文传输的连贯性。一旦出现某一方发出的TCP报文丢失,便无法继续”握手”,以此确保了”三次握手”的顺利完成。
————————————————
【原文链接:https://blog.csdn.net/qq_48508278/article/details/122588669】
四次挥手
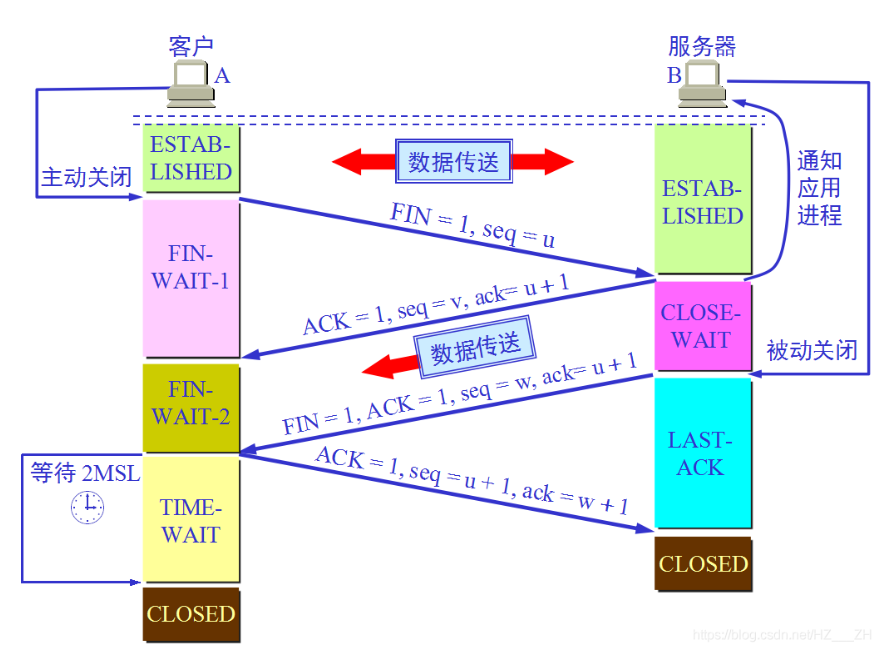
所谓的四次挥手即TCP连接的释放(解除)。连接的释放必须是一方主动释放,另一方被动释放。挥手之前主动释放连接的客户端结束ESTABLISHED阶段。随后开始“四次挥手”:
a:首先客户端想要释放连接,向服务器端发送一段TCP报文,其中:
标记位为FIN,表示“请求释放连接“;
序号为Seq=U;
随后客户端进入FIN-WAIT-1阶段,即半关闭阶段。并且停止在客户端到服务器端方向上发送数据,但是客户端仍然能接收从服务器端传输过来的数据。
注意:这里不发送的是正常连接时传输的数据(非确认报文),而不是一切数据,所以客户端仍然能发送ACK确认报文。
b:服务器端接收到从客户端发出的TCP报文之后,确认了客户端想要释放连接,随后服务器端结束ESTABLISHED阶段,进入CLOSE-WAIT阶段(半关闭状态)并返回一段TCP报文,其中:
标记位为ACK,表示“接收到客户端发送的释放连接的请求”;
序号为Seq=V;
确认号为Ack=U+1,表示是在收到客户端报文的基础上,将其序号Seq值加1作为本段报文确认号Ack的值;
随后服务器端开始准备释放服务器端到客户端方向上的连接。
客户端收到从服务器端发出的TCP报文之后,确认了服务器收到了客户端发出的释放连接请求,随后客户端结束FIN-WAIT-1阶段,进入FIN-WAIT-2阶段
前”两次挥手”既让服务器端知道了客户端想要释放连接,也让客户端知道了服务器端了解了自己想要释放连接的请求。于是,可以确认关闭客户端到服务器端方向上的连接了
c:服务器端自从发出ACK确认报文之后,经过CLOSED-WAIT阶段,做好了释放服务器端到客户端方向上的连接准备,再次向客户端发出一段TCP报文,其中:
(第二次挥手 服务器端回复 确认收到 客户端想要释放连接的请求 返回ACK,但是 服务端还有些数据的处理,所以不能马上断开连接,所以需要第三次挥手 即服务端发送 FIN 释放连接的标志位)
标记位为FIN,ACK,表示“已经准备好释放连接了”。注意:这里的ACK并不是确认收到服务器端报文的确认报文。
序号为Seq=W;
确认号为Ack=U+1;表示是在收到客户端报文的基础上,将其序号Seq值加1作为本段报文确认号Ack的值。
随后服务器端结束CLOSE-WAIT阶段,进入LAST-ACK阶段。并且停止在服务器端到客户端的方向上发送数据,但是服务器端仍然能够接收从客户端传输过来的数据。
d:客户端收到从服务器端发出的TCP报文,确认了服务器端已做好释放连接的准备,结束FIN-WAIT-2阶段,进入TIME-WAIT阶段,并向服务器端发送一段报文,其中:
标记位为ACK,表示“接收到服务器准备好释放连接的信号”。
序号为Seq=U+1;表示是在收到了服务器端报文的基础上,将其确认号Ack值作为本段报文序号的值。
确认号为Ack=W+1;表示是在收到了服务器端报文的基础上,将其序号Seq值作为本段报文确认号的值。
随后客户端开始在TIME-WAIT阶段等待2MSL
服务器端收到从客户端发出的TCP报文之后结束LAST-ACK阶段,进入CLOSED阶段。由此正式确认关闭服务器端到客户端方向上的连接。
客户端等待完2MSL之后,结束TIME-WAIT阶段,进入CLOSED阶段,由此完成“四次挥手”。
e:总结
后“两次挥手”既让客户端知道了服务器端准备好释放连接了,也让服务器端知道了客户端了解了自己准备好释放连接了。于是,可以确认关闭服务器端到客户端方向上的连接了,由此完成“四次挥手”。
————————————————
【原文链接:https://blog.csdn.net/qq_48508278/article/details/122691189】
为什么握⼿是三次,挥⼿是四次?
对于握⼿:握⼿只需要确认双⽅通信时的初始化序号,保证通信不会乱序。
(第三次握⼿必要性:为了防止旧的重复连接引起连接混乱问题。假设服务端的确认丢失,连接并未断开,客户机超时重发连接请求,这样服务器会对同⼀个客户机保持多个连接,造成资源浪费。)
对于挥⼿:TCP是双⼯的,所以发送⽅和接收⽅都需要FIN和ACK。只不过有⼀⽅是被动的,所以看上去就成了4次挥⼿。
为什么客户端在TIME-WAIT装填必须等待2MSL时间呢?
第一,为了保证客户端发送的最后一个ACK报文段能够到达服务端:
1 | 客户端发送的ACK报文段可能丢失,因而使服务器收不到对自己已发送的释放连接报文段的确认。服务器会重传连接释放报文段,而客户端就能在2MSL时间内收到这个重传FIN+ACK报文段。接着客户端重传一次确认,重新启动2MSL计时器。最终,客户端和服务器端都能进入CLOSE状态。 |
第二,防止已经失效的连接请求报文段出现在本连接中:
1 | 客户端在发送完最后一个ACK报文段后,再经过时间2MSL。就可以使本连接持续的时间内所产生的所有报文段都在网络中消失。这样就可以在下一个新的连接中不会出现这种旧的连接请求报文段。 |
————————————————
原文链接:https://blog.csdn.net/HZ___ZH/article/details/110134076
浏览器输入url的全过程
- 当输入url时,浏览器作为客户端首先会请求DNS服务器,通过DNS获取相应的域名和IP(应用层)
- 通过IP地址找到对应的服务器,然后建立TCP连接
- 浏览器向服务端发送http请求包(应用层 -> 传输层 -> 网络层 -> 数据链路层))
- 服务端接受到http请求包后开始处理请求包(数据链路层 -> 网络层 -> 传输层 -> 应用层)
- 在服务器收到请求之后,服务器调用自身服务,返回响应包
- 浏览器接收到响应包后开始进行页面的渲染
————————————————
原文链接:https://blog.csdn.net/zhangjing1019/article/details/115414175
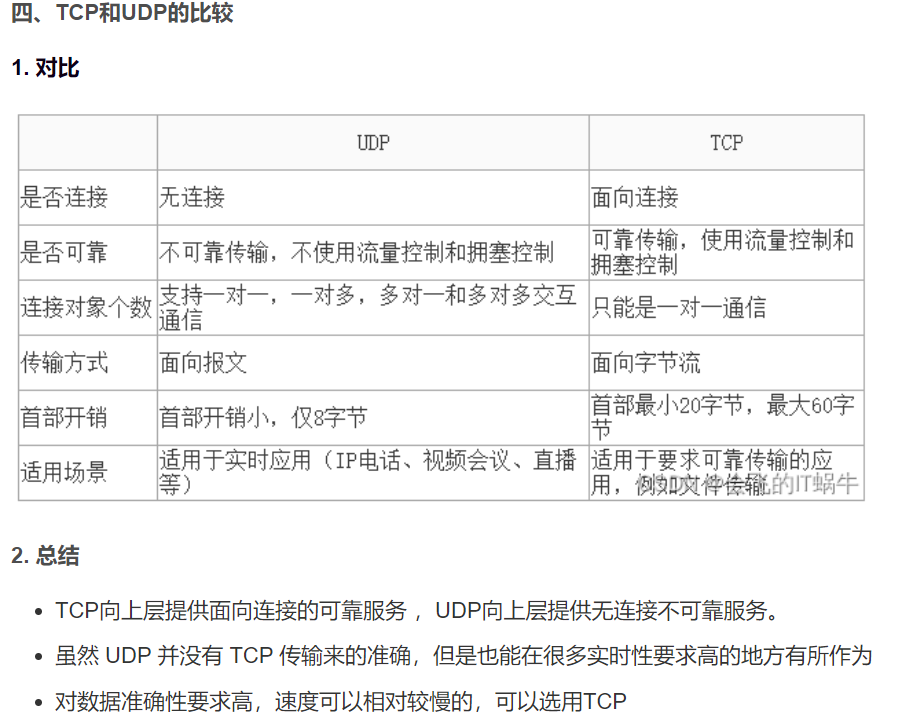
TCP与UDP的区别
http与https的区别
- HTTP 明文传输,数据都是未加密的,安全性较差,HTTPS(SSL+HTTP) 数据传输过程是加密的,安全性较好。
- 使用 HTTPS 协议需要到 CA(Certificate Authority,数字证书认证机构) 申请证书,一般免费证书较少,因而需要一定费用。证书颁发机构如:Symantec、Comodo、GoDaddy 和 GlobalSign 等。
- HTTP 页面响应速度比 HTTPS 快,主要是因为 HTTP 使用 TCP 三次握手建立连接,客户端和服务器需要交换 3 个包,而 HTTPS除了 TCP 的三个包,还要加上 ssl 握手需要的 9 个包,所以一共是 12 个包。
- http 和 https 使用的是完全不同的连接方式,用的端口也不一样,前者是 80,后者是 443。
- HTTPS 其实就是建构在 SSL/TLS 之上的 HTTP 协议,所以,要比较 HTTPS 比 HTTP 要更耗费服务器资源。
https加密流程总结:
SSL采用混合加密,融合了上量两种加密方式的优点。
混合加密:先使用非对称加密保护一个对称密钥的协商过程,然后对称密钥协商完成之后,使用对称加密传输。
实际SSL加密是将身份验证和加密传输两步骤合在一起,总流程为:
- 需要被验证身份的一方生成一对密钥
- 去权威机构生成一个CA证书(并且将公钥交给权威机构)
- 通信前将CA证书发给对端(证书会包含机构信息和公钥信息)
- 对端对证书进行解析,对当前通信方身份进行验证。
- 身份验证通过之后,使用混合加密方式传输数据:即先使用非对称加密方式协商对称密钥,对称密钥协商完成之后,使用对称加密传输。其中使用非对称加密方式协商对称密钥的过程为:1.使用公钥加密数据(一个随机数+对称密钥算法列表)发送给验证方;2.验证方回复数据(一个随机数+对称密钥算法列表);3.双方使用两个随机送以及对称密钥算法列表计算出一对密钥。
————————————————
原文链接:https://blog.csdn.net/S5242/article/details/124165507
session与cookie的区别

post和get的区别
HTTP协议中的两种发送请求的方法,本质上都是在进行TCP连接.
最直观的区别就是GET把参数包含在URL中,POST通过request body传递参数。
GET产生一个TCP数据包;POST产生两个TCP数据包:
对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据);
而对于POST,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok(返回数据)。
————————————————
原文链接:https://blog.csdn.net/song854601134/article/details/111053528
建议:
1、get方式的安全性较Post方式要差些,包含机密信息的话,建议用Post数据提交方式;
2、在做数据查询时,建议用Get方式;而在做数据添加、修改或删除时,建议用Post方式;
案例:一般情况下,登录的时候都是用的POST传输,涉及到密码传输,而页面查询的时候,如文章id查询文章,用get 地址栏的链接为:article.php?id=11,用post查询地址栏链接为:article.php, 不会将传输的数据展现出来。
B树和B+树
B树和B+树都是在二叉树的基础上面变形而来,B+树是B树的变种,都是平衡多路查找树。不同的一点是B树允许每个节点有更多的子节点,在B树中叶子节点和非叶子节点上都存储了数据。
B+树是对B树的一种变形树,B+树只是在叶子节点上面存储了数据,并且叶子节点之间是使用双向链表连接起来的,适合范围查询。
B+树的层级一般在2–4层,经行磁盘io的次数和层数相同。
在B+树中,所有记录节点都是按键值的大小顺序存放在同一层的叶子节点。
————————————————
原文链接:https://blog.csdn.net/qq_59245985/article/details/126780502
使用B+树的好处
由于B+树的内部节点只存放键,不存放值,因此,一次读取,可以在内存页中获取更多的键,有利于更快地缩小查找范围。 B+树的叶节点由一条链相连,因此,当需要进行一次全数据遍历的时候,B+树只需要使用O(logN)时间找到最小的一个节点,然后通过链进行O(N)的顺序遍历即可。而B树则需要对树的每一层进行遍历,这会需要更多的内存置换次数,因此也就需要花费更多的时间。
————————————————
原文链接:https://blog.csdn.net/qq_44918090/article/details/120278339
数据库为什么使用B+树而不是B树

列表,元组和字典的区别
列表——list:类型相同的元素,可以改变元素的值,即可进行增删改查操作。用中括号表示[num1,num2,num3]
元组——tuple:和列表功能相似,但不能改变其元素的值,即不可以进行增删改的操作,只能执行查询操作。用小括号表示(num1,num2,num3)
字典——infor:类型不同的元素,由键值对组成,与列表一样可以进行增删改查。用大括号表示{key1:value1,key2:value2,key3:value3}
列表中的元素可以是元组和字典。
另外,在python中,大部分参数是不可以被修改的,如字符串,数字,元组,而列表和字典中的内容是可以被修改的,所以在字典中,列表和字典是不可以被当作key值的
————————————————
原文链接:https://blog.csdn.net/weixin_43652535/article/details/84996978
爬虫的基本流程
1.发起请求:
通过HTTP库向目标站点发起请求,即发送一个Request,请求可以包含额外的headers、data等信息,然后等待服务器响应。这个请求的过程就像我们打开浏览器,在浏览器地址栏输入网址:www.baidu.com,然后点击回车。这个过程其实就相当于浏览器作为一个浏览的客户端,向服务器端发送了 一次请求。
2.获取响应内容:
如果服务器能正常响应,我们会得到一个Response,Response的内容便是所要获取的内容,类型可能有HTML、Json字符串,二进制数据(图片,视频等)等类型。这个过程就是服务器接收客户端的请求,经过解析发送给浏览器的网页HTML文件。
3.解析内容:
得到的内容可能是HTML,可以使用正则表达式,网页解析库进行解析。也可能是Json,可以直接转为Json对象解析。可能是二进制数据,可以做保存或者进一步处理。这一步相当于浏览器把服务器端的文件获取到本地,再进行解析并且展现出来。
4.保存数据:
保存的方式可以是把数据存为文本,也可以把数据保存到数据库,或者保存为特定的jpg,mp4 等格式的文件。这就相当于我们在浏览网页时,下载了网页上的图片或者视频。
————————————————
原文链接:https://blog.csdn.net/weixin_42223833/article/details/90142759
手机扫描二维码的测试用例
二维码概述
二维码本身就是一个URL,只是通过QR码的形式把URL和用户身份信息转换成二进制的0和1,二维码中黑色的色素块代表1,白色的色素块代表0,我们通过相机扫码,就获取了二维码中的URL
测试用例罗列(含扫码支付的相关内容)
界面测试:
界面的按钮和文字说明是否清晰、正确;
界面的设计风格是否符合大众审美,对用户操作是否友好;
功能测试:
扫描成功是否有提示
扫描失败是否有提示
只扫描一半时,是否扫描成功
打开扫描功能一段时间后没有扫描任何二维码,是否有提示用户或自动退出扫描功能
是否支持相册获取二维码,当扫描不是二维码时提示是否正确
是否有点亮功能(考虑到环境较暗的情况)
不是该类型的二维码是否提示正确
是否支持页面之间的链接跳转,跳转是否正确
对 付款码/非收付款码/旧码/手动涂改过的扫码校验
二维码尺寸/清晰度/完整性 扫码校验
二维码扫描距离/角度/阴暗,高亮环境下校验
二维码有效期验证
失效二维码是否可以扫
二维码生成多个扫描后是否正常显示
二维码付款功能的额外测试
验证本人未输入的指纹校验
验证本人已输入的指纹校验
添加新卡支付校验
实名支付本人姓名加密校验
付款页面添加备注校验
取消支付校验
零钱不足切换银行卡支付校验
支付次数限度校验
指纹错误验证次数上线校验
支付凭证校验
输入金额,支付金额 扣款金额一致性校验
扣款后余额校验
查看账单详情校验
密码是否为密文 为空 为零 以及长度校验
密码错误提示及错误次数上限校验
输入金额上下限校验,校验
输入金额为空,为零为
账户余额不足时的校验
单笔超出上限校验
当日超出上限校验
二维码扫码信息正确特殊字符 校验,
输入金额:
密码
金额
切换指纹支付校验
支付到账时间校验
性能测试:
没网的状态下扫码校验
网络不好时切换网络校验
多人同时扫码校验
扫描后响应时间的测试
扫码跳转过程中断测试(扫码时来电/来信息/邮件等)
扫码后切换应用程序,看是否会闪退,黑屏,跳转回去是否会跳到相应的链接
兼容性测试:
使用不同品牌手机/不同手机像素/不同软件/不同软件版本扫码校验
安全性测试:
是否会泄漏用户账号新消息;
盗号和外挂考虑。
————————————————
版权声明:本文为CSDN博主「自在的旅者」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_54696666/article/details/120722161
说一下 B/S 和 C/S 架构的区别
**B/S(Browser/Server)**指浏览器和服务器端,在客户机端不用装专门的软件,只要一个浏览器即可。
**C/S(Client/Server)**指客户机和服务器,在客户机端必须装客户端软件后才能访问服务器,如 QQ、飞信等。
1)B/S 和 C/S 各有千秋,他们都是当前非常重要的计算架构
2)在适用 Internet、维护工作量等方面,B/S 比 C/S 要强得多
3)B/S 架构需要重点考虑系统在不同的浏览器中的兼容性问题,在 IE 个版本浏览器(IE6/7/8/9/10/11/12)、火狐浏览器、谷歌浏览器
4)C/S 架构需要考虑系统的安装、卸载、升级、支持哪种平台(如win32、win64、linux 等)
=================
*MySQL是基于c/s 架构
String、StringBuffer的区别
STRING的长度是不可变的,STRINGBUFFER的长度是可变的。如果你对字符串中的内容经常进行操作,特别是内容要修改时,那么使用StringBuffer,如果最后需要String,那么使用StringBuffer的toString()方法
使用 StringBuffer 主要就是在性能上的考虑。 String 是一种非常常用的数据类型,但由于 String 是不可变对象,在进行 String 的相关操作的时候会产生许多临时的 String 对象。而 StringBuffer 在操作上是在一个缓冲中进行的,性能当然优越得多。不过,一般做为简单的字符串传递和其它操作,只不要改变字符串内容的操作,用 String 效率会高一些。
Springboot常用注解
Controller 相关注解
@Controller
控制器,处理http请求。
@RestController 复合注解
@RestController注解相当于@ResponseBody+@Controller合在一起的作用,RestController使用的效果是将方法返回的对象直接在浏览器上展示成json格式.
@RequestBody
通过HttpMessageConverter读取Request Body并反序列化为Object(泛指)对象
@RequestMapping
@RequestMapping 是 Spring Web 应用程序中最常被用到的注解之一。这个注解会将 HTTP 请求映射到 MVC 和 REST 控制器的处理方法上
@Controller 只是定义了一个控制器类,而使用@RequestMapping 注解的方法才是真正处理请求的处理器
@GetMapping
用于将HTTP get请求映射到特定处理程序的方法注解,是@RequestMapping(method = RequestMethod.GET)的缩写
@PostMapping
用于将HTTP post请求映射到特定处理程序的方法注解,是@RequestMapping(method = RequestMethod.POST)的缩写
Springboot
特性
Create stand-alone Spring applications
创建独立的Spring应用程序
Embed Tomcat, Jetty or Undertow directly (no need to deploy WAR files)
直接嵌入Tomcat、Jetty或Undertow(不需要部署WAR文件)
Provide opinionated ‘starter’ dependencies to simplify your build configuration
提供有主见的 “启动器 “依赖,以简化你的构建配置
Automatically configure Spring and 3rd party libraries whenever possible
尽可能地自动配置Spring和第三方库
Provide production-ready features such as metrics, health checks, and externalized configuration
提供生产就绪的功能,如度量、健康检查和外部化配置
Absolutely no code generation and no requirement for XML configuration
完全没有代码生成,也不需要XML配置
Spring Web MVC
Spring Web MVC is the original web framework built on the Servlet API
Spring Web MVC是建立在Servlet API上的原始Web框架。
Dubbo微服务框架
Dubbo是一款高性能、轻量级的开源Java RPC框架,它提供了三大核心能力:面向接口的远程方法调用,智能容错和负载均衡,以及服务自动注册和发现。
RPC是一个跨应用层+传输层的网络通信服务,调用者主要设置应用层里面的传输协议,配置相关属性,调用时将数据传入并通过该协议发送
Dubbo框架负载均衡策略
加权随机:根据随机算法选择服务端,并且对其加权以获得更多调用概率
最小活跃数:获得请求+1,结束请求-1,因此最小活跃数表示压力最小
一致性hsh:hash函数根据请求信息落到某一服务器,信息不变,hash处理结果不变
加权轮询:将权重和轮询结合
Dubbo框架服务降级
当服务器压力剧增的情况下,根据实际业务情况及流量,对一些服务和页面有策略的不处理或换种简单的方式处理,从而释放服务器资源以保证核心交易正常运作或高效运作。
Dubbo框架服务容错
在服务提供者工程集群环境中某节点出现故障时保障消费者仍可以正常执行调用机制。dubbo的容错机制主要有6类:
失败重试,无效自动切换(Failover Cluster 也是默认机制 )
快速失败,只发起一次调用(Failfast Cluster 适合非幂等性操作 )
失败安全,忽略异常(Failsafe Cluster)
失败自动恢复(Failback Cluster)
并行调用多个服务器(Forking Cluster)
广播调用所有提供者(Broadcast Cluster)
————————————————
Linux
pwd 显示工作路径
shutdown -h now 关闭系统 /halt 关闭系统
shutdown -r now 重启 / reboot 重启
systemctl stop firewalld 关闭防火墙
ip addr 查看ip地址
1、cd命令:
这是一个非常基本,也是大家经常需要使用的命令,它用于切换当前目录,它的参数是要切换到的目录的路径,可以是绝对路径,也可以是相对路径。如:
cd /home 进入根目录下面的home目录
cd home 进入当前目录下的home目录
cd .. 返回上一层目录
cd ../.. 返回上两级目录
cd / 返回跟目录
cd - 返回上次所在的目录
2、ls命令:
这是一个非常有用的查看文件与目录的命令,list之意,它的参数非常多,下面就列出一些我常用的参数吧,如下:
ls 查看目录中的文件
ls -a 列出全部的文件,连同隐藏文件(开头为.的文件)一起列出来
ls -l 显示文件和目录的详细资料
3、mkdir命令:创建
mkdir dir1 创建一个叫做 ‘dir1’ 的目录’
mkdir dir1 dir2 同时创建两个目录
4、rm命令:删除
rm -f file1 删除一个叫做 ‘file1’ 的文件’
rmdir dir1 删除一个叫做 ‘dir1’ 的目录’ (空目录才能删除)
rm -rf dir1 删除一个叫做 ‘dir1’ 的目录并同时删除其内容
rm -rf dir1 dir2 同时删除两个目录及它们的内容
5、mv命令:
该命令用于移动文件、目录或更名,move之意,它的常用参数如下:-f 如果目标文件已经存在,不会询问而直接覆盖
mv file1 file2 把文件file1重命名为file2
mv file1 file2 dir 把文件file1、file2移动到目录dir中
6、cp命令:
该命令用于复制文件,copy之意,它还可以把多个文件一次性地复制到一个目录下, 它的常用参数如下:
cp -a file1 file2 连同文件的所有特性把文件file1复制成文件file2
cp dir/* . 复制一个目录下的所有文件到当前工作目录
cp -a /tmp/dir1 . 复制一个目录到当前工作目录
cp -a dir1 dir2 复制一个目录
7、find命令:
find是一个基于查找的功能非常强大的命令
find / -name file1 从 ‘/‘ 开始进入根文件系统搜索文件和目录
find / -user user1 搜索属于用户 ‘user1’ 的文件和目录
find /home/user1 -name *.bin 在目录 ‘/ home/user1’ 中搜索带有’.bin’ 结尾的文件
find /usr/bin -type f -atime +100 搜索在过去100天内未被使用过的执行文件
find /usr/bin -type f -mtime -10 搜索在10天内被创建或者修改过的文件
8、ps命令:
该命令用于将某个时间点的进程运行情况选取下来并输出,process之意,它的常用参数如下:
-A :所有的进程均显示出来
-a :不与terminal有关的所有进程
-u :有效用户的相关进程
-x :一般与a参数一起使用,可列出较完整的信息
-l :较长,较详细地将PID的信息列出
其实我们只要记住ps一般使用的命令参数搭配即可,它们并不多,如下:
ps aux 查看系统所有的进程数据
ps ax 查看不与terminal有关的所有进程
ps -lA 查看系统所有的进程数据
ps axjf 查看连同一部分进程树状态
9、kill命令:
该命令用于向某个工作(%jobnumber)或者是某个PID(数字)传送一个信号,它通常与ps和jobs命令一起使用,它的基本语法如下:
kill -signal PID
signal的常用参数如下:注:最前面的数字为信号的代号,使用时可以用代号代替相应的信号。
1:SIGHUP,启动被终止的进程
2:SIGINT,相当于输入ctrl+c,中断一个程序的进行
9:SIGKILL,强制中断一个进程的进行
15:SIGTERM,以正常的结束进程方式来终止进程
17:SIGSTOP,相当于输入ctrl+z,暂停一个进程的进行
例如:
# 以正常的结束进程方式来终于第一个后台工作,可用jobs命令查看后台中的第一个工作进程
kill -SIGTERM %1
# 重新改动进程ID为PID的进程,PID可用ps命令通过管道命令加上grep命令进行筛选获得
kill -SIGHUP PID
10、tar命令:
该命令用于对文件进行打包,默认情况并不会压缩,如果指定了相应的参数,它还会调用相应的压缩程序(如gzip和bzip等)进行压缩和解压。它的常用参数如下:
- 压缩:tar -jcv -f filename.tar.bz2 要被处理的文件或目录名称
- 查询:tar -jtv -f filename.tar.bz2
- 解压:tar -jxv -f filename.tar.bz2 -C 欲解压缩的目录
11、chmod命令:
该命令用于改变文件的权限,一般的用法如下:
chmod -R 777 chmod -R 777 意思就是将当前目录及目录下所有文件都给予777权限(所有权限)
查看文件内容
cat file1 从第一个字节开始正向查看文件的内容
tac file1 从最后一行开始反向查看一个文件的内容
more file1 查看一个长文件的内容
less file1 类似于 ‘more’ 命令,但是它允许在文件中和正向操作一样的反向操作
head -2 file1 查看一个文件的前两行
tail -2 file1 查看一个文件的最后两行
tail -f /var/log/messages 实时查看被添加到一个文件中的内容
grep
Linux 命令三剑客,sed、grep、awk。
- sed:擅长数据修改。
- grep:擅长数据查找定位。
- awk:擅长数据切片,数据格式化,功能最复杂。 grep 可以说是这三个命令中的红人,是我们日常使用频率最高的命令,下面和锅锅一起来搞定它。
作用:文本搜索工具,根据用户指定的“模式(过滤条件)”对目标文本逐行进行匹配检查,打印匹配到的行.
模式:由正则表达式的元字符及文本字符所编写出的过滤条件﹔
grep 命令常用可选参数
- -n # 显示行号。
- -i # 不区分大小写。
- -c # 统计匹配行,命中查找字符串的总行数。
- -v # 显示不包含匹配文本的所有行。
- -r # 递归处理。
- -E # 使用正则表达式作为匹配进行查找(注:-e 没有-E 支持的完整)。
- –include # 指定匹配的文件类型。
- –exclude # 过滤不需要匹配的文件类型。 使用示例:
- grep -i “error” info.log
- grep -in “error” info.log #不区分大小写,并显示行号。
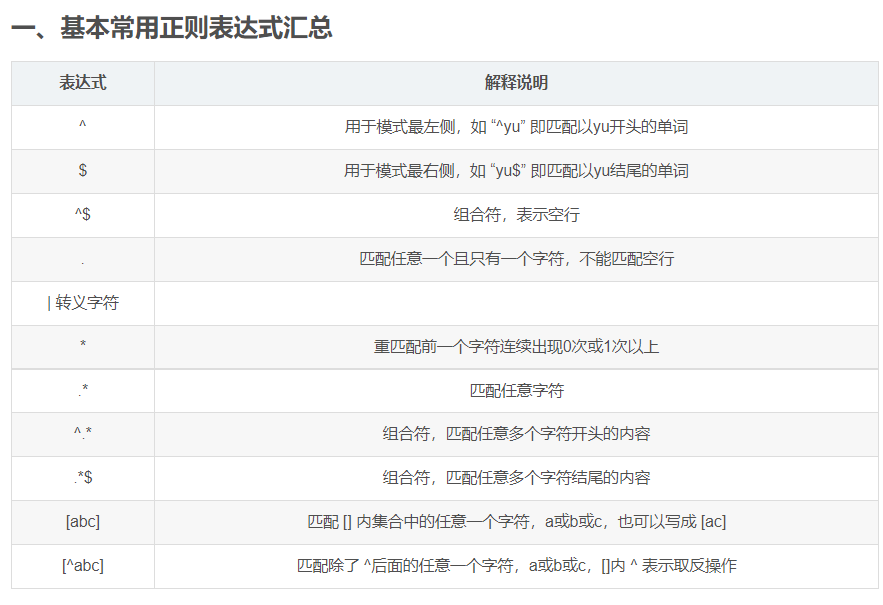
基本常用正则表达式汇总
Kmeans和KNN的区别
两种算法之间的根本区别是,K-means本质上是无监督学习,而KNN是监督学习;K-means是聚类算法,KNN是分类(或回归)算法。
KMEAN算法把一个数据集分割成簇,使得形成的簇是同构的,每个簇里的点相互靠近。该算法试图维持这些簇之间有足够的可分离性。由于无监督的性质,这些簇没有任何标签。
KNN算法尝试基于其k(可以是任何数目)个周围邻居来对未标记的观察进行分类。它也被称为懒惰学习法,因为它涉及最小的模型训练。因此,它不用训练数据对未看见的数据集进行泛化。
KNN的算法原理:分类算法,监督学习,数据集是带Label的数据,没有明显的训练过程,基于Memory-based-learningK值含义:对于一个样本X,要给它分类,首先从数据集中,在X附近找离它最近的K个数据点,将它划分为归属于类别最多的一类。K-means的算法原理:聚类算法,非监督学习,数据集是无Label,杂乱无章的数据,有明显的训练过程,K值含义:K是事先设定的数字,将数据集分为K个簇,需要依靠人的先验知识。
XGBoost
GBoost [2] 是对梯度提升算法的改进,求解损失函数极值时使用了牛顿法,将损失函数泰勒展开到二阶,另外损失函数中加入了正则化项。训练时的目标函数由两部分构成,第一部分为梯度提升算法损失,第二部分为正则化项。损失函数定义为 :
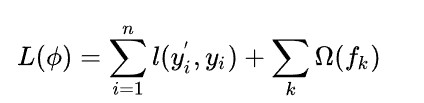
其中n为训练函数样本数,l是对单个样本的损失,假设它为凸函数,$y’_i$为模型对训练样本的预测值,$y_i$为训练样本的真实标签值。正则化项定义了模型的复杂程度:
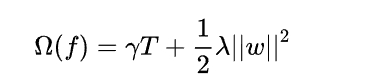
其中,$\gamma$和$\lambda$为人工设置的参数,w为决策树所有叶子节点值形成的向量,T为叶子节点数。
